POSSE



POSSE is an abbreviation for Publish (on your) Own Site, Syndicate Elsewhere, the practice of posting content on your own site first, then publishing copies or sharing links to third parties (like social media silos) with original post links to provide viewers a path to directly interacting with your content.
▶️ watch Zach’s 1min* video intro to POSSE
Why
Let your friends read your posts, their way. POSSE lets your friends keep using whatever they use to read your stuff (e.g. social media silos like Instagram, Tumblr, Twitter, Neocities, etc.).
Stay in touch with friends now, not some theoretical future. POSSE is about staying in touch with current friends now, rather than the potential of staying in touch with friends in the future.
Friends are more important than federation. By focusing on relationships that matter to people rather than architectural ideals, from a human perspective, POSSE is more important than federation. Additionally, if federated approaches take a POSSE approach first, they will likely get better adoption (everyone wants to stay in touch with their friends), and thereby more rapidly approach that federated future.
POSSE is beyond blogging. It's a key part of why and how the IndieWeb movement is different from just "everyone blog on their own site", and also different from "everyone just install and run (YourFavoriteSocialSoftware)" etc. monoculture solutions.
Why In General
POSSE is considered a robust and preferable syndication model for the following reasons:
- Reduce 3rd party dependence. By posting directly to your own site, you're not dependent on 3rd Party services to do so -- if you can access your site, you can publish your content. On the contrary with PESOS, when the 3rd party site is down, you are unable to add content.
- Ownership. By posting first on your own site, you create a direct ownership chain that can be traced back to you without any intervening 3rd party services (silos) TOS's getting in the way (which is a vulnerability of PESOS).
- Own canonical URLs to your content. Canonical URLs to your content are on your domain.
- Copies can cite the original. By posting content first to your own site (and thus creating a permalink for it), copies that you post on 3rd Party services can link or cite the original on your site (see syndication_formats and POSSE Notes to Twitter)
- Better search. Searching public content on your own domain (with any web search engine of your choice) works better than depending on silos exclusively to search your posts (e.g. Twitter for a while only showed recent tweets in search results. Facebook still has very poor search results).
- backfeed can be used to pull in (reverse syndicate) responses from other services
- allows taking advantage of other services' social layers and aggregation features while storing the canonical copy of your content on your own site
- ...
Why Link To Your Original
Common POSSE practice is to link from POSSE copies to your original, using a permashortlink. Here are a few reasons why:
- Discovery of your original content. discovery of your original content from the copies on 3rd party services is enabled by the permashortlinks to your originals posted on said services
- Subvert spammers who copy your posts. When spammers (e.g. @sin3rss) mindlessly copy from your POSSE copies and repost, they also copy the link back to the original, and thus provide more distribution for people to find and view your original post. "2011-01-09 internet aikido" of a sort.
- Better ranking for your original posts. If/when your POSSE copies are themselves copied by others and (re)posted elsewhere (e.g. manual retweets, RSS bots etc.), when the copies link to your original posts, search engines figure that out by following those links back to the original and ranking it higher.
How to
How to implement
This section is for web developers implementing POSSE.
In General
In general, when your content posting software posts something, it should also post a copy to the silo destinations of your choice, with an original post link (e.g. permashortlink or permashortcitation) back to your original.
The details of how to do so vary per destination. See the silo-specific sections below.
Once you have posted the copy to the silo, you should:
- link to the syndicated copy from the original in a posts-elsewhere section on your post.
User Interface
The best user interface (UI) is automatic, dependable, and invisible. If you can implement POSSEing in a way that always does exactly what you want, predictably, then no explicit UI is needed.
Preview
One way to provide more predictability and inspire confidence is to show what will be POSSEd (within the limitations of the destination) as a preview before publishing
(needs screenshot)
Twitter is perhaps the most popular POSSE destination and a good place to start.
If you can start posting notes (tweets) to your own site and POSSEing to Twitter, instead of posting directly to Twitter, you have taken a big step towards owning your data.
Details:
- API Access - posting new tweets works nicely due to permanent API tokens, and the return value contains a URL to the posted
- As of 2022-11, Twitter is rejecting new API access for applications used to POSSE/backfeed on the grounds that they may violate twitter’s rules and/or policies —
 Barnaby Walters
Barnaby Walters
- As of 2022-11, Twitter is rejecting new API access for applications used to POSSE/backfeed on the grounds that they may violate twitter’s rules and/or policies —
- Supports very complete web action endpoints, so semi-manual posting is easy to implement
- What are these endpoints? Is this still the case in 2022? — Barnaby Walters
- What are these endpoints? Is this still the case in 2022? —
See POSSE to Twitter for details on how to POSSE both notes and articles (blog posts) to Twitter.
There are two options for POSSEing to Facebook currently:
- Manually crosspost
- Semi-automatically with the Bridgy browser extension for Facebook
Medium
- You can create posts via the posts API
- Medium also supports manual POSSE via the Import Post function, which preserves rel-canonical links to the original URL
 Shane Becker and
Shane Becker and  Ben Werdmüller manually POSSE to Medium
Ben Werdmüller manually POSSE to Medium Chris Aldrich uses the WordPress Medium Plugin to POSSE to Medium. They also support bulk migration (aka mass POSSE) for porting across lots of posts after which posts can be POSSEd by means of their plugin.
Chris Aldrich uses the WordPress Medium Plugin to POSSE to Medium. They also support bulk migration (aka mass POSSE) for porting across lots of posts after which posts can be POSSEd by means of their plugin. Aaron Gustafson Wrote a Jekyll plugin to POSSE to Medium.
Aaron Gustafson Wrote a Jekyll plugin to POSSE to Medium.
WordPress
- How does veganstraightedge.com do it? (all his articles are manually POSSEd to WordPress.com)
- Chris Aldrich uses a WordPress plugin WordPress Crosspost to POSSE from a self-hosted WordPress install to WordPress.com.
Plain Text Notes
Some destinations (e.g. SMS or push notifications) may require a pure plain text representation.
- h-entry_to_text is a method of generating a plain text representation from an arbitrary h-entry
Software
Software and libraries to implement POSSE:
- PHP
- The POSSE namespace in php-helpers (might be moved to a separate package) contains various truncation, preparation and syndication functions including HTML => plaintext µblog syntax converter
- Python
- SiloRider is a command-line tool, implemented in Python, that lets you implement POSSE to various services (Twitter and Mastodon as of 2018-08-01).
- Feed2Toot is another command-line python tool that parses any number of RSS feeds and posts their content on ActivityPub based services (tested with: Mastodon, Pleroma). Contains some neat bells and whistles like advanced post filtering, numerous options for feed parsing and toot formatting.
Services
- Bridgy Publish is POSSE-as-a-service. It supports Twitter, Flickr, GitHub and Mastodon. You can use it interactively or programmatically via webmention.
- Mugged Tweets - will POSSE a note to a mug (may require first POSSEing to Twitter)
- IFTTT allows automatically reposting content with an RSS or Atom feed to a number of silos incuding Twitter, Tumblr, and Facebook
Publishing Flows
There's at least two ways to implement a POSSE content posting flow:
Client to site to silo
- The user writes a piece of content using a publishing client
- Optional: client provides UI for selecting which 3rd party services to push to if it knows about them, with optional customizations for per service
- Having finished the content, the user publishes content to their server (optionally: with metadata of which 3rd party services and any customizations thereof)
- Optional: client can generate a permalink knowing the state of the server, and publish to that permalink
- The server publishes the content, generates a permalink and summary (and/or customized content suited to 3rd party services) if necessary
- The server posts copies with permalinks to 3rd party services
Advantages:
- User only has to interact with one site over the internet, their own
- Syndication can be done fully automatically by the server
Disadvantages:
- any?
Client to site and silo
- The user writes a piece of content using a publishing client
- Having finished the content, the user publishes it to their server
- The client queries the server for the URL of the content it just pushed
- The publishing client presents the user with an interface for selecting:
- Which 3rd party services to publish to
- The exact content published to the services, pre-filled with a summary based on the produced content
- The user selects the services and submits the form
- The publishing client posts the content summaries out to the 3rd party services
Advantages:
- More user control over timing and editing of copies of content to 3rd party services
Disadvantages:
- Syndication requires a manual step each time
- Dependent on client connectivity directly to 3rd party services (problematic in flakey mobile situations, or when client is publishing using domain-censored internet access).
IndieWeb Examples
The following IndieWebCamp participants' sites support a POSSE architecture. If you have an implementation, add it, make screenshots or a screencast or blog about it and post the details/link here. In date order (earliest first) :
Tantek
Tantek.com as of 2010-01-01[1] (2010-01-26 Twitter syndication started[2] and caught up[3][4]). Tantek Çelik implemented POSSE in Falcon on tantek.com.
- all self-hosted posts are openly with PuSH v0.4 + h-feed and Atom real-time syndicated with a PubsubHubbub hub to StatusNet, other subscribers etc. (also to Google Buzz til it shutdown)
- note (and article titles), reply, RSVP posts are snowflake copied by the personal site server to Twitter with permashortlink citation links/references (see Whistle for details) back to the original. Copies of notes to Twitter are also automatically recopied from there to Facebook.
- likes of tweets are "copied" (more like propagated) to Twitter using Bridgy publish
Barnaby Walters
Waterpigs.co.uk as of 2012-03-12. Barnaby Walters implemented POSSE over at waterpigs.co.uk
- as of 2012-09-25 all collections (notes, articles, activity) are PuSH-subscribable feeds.
- Using the Client to Server to 3rd Parties flow --Waterpigs.co.uk 06:08, 25 September 2012 (PDT)
- Syndicating to Twitter + Facebook
- As of 2014-06-19 Taproot can now optionally post additional POSSE tweets when updating a note or article — example of updated note and POSSE tweet for the update. Note that Bridgy successfully backfeeds silo interactions from the update tweet as well as the original POSSE tweet
Brennan Novak
brennannovak.com as of 2012-07-01[5][6]. Brennan Novak implemented POSSE on his site brennannovak.com with copies posted to Twitter and Facebook
Aaron Parecki
aaronparecki.com as of 2012-08-19[7][8]. Aaron Parecki implemented POSSE on his site aaronparecki.com with copies posted to Twitter containing permashortlinks back to originals on his own site.
- as of 2012-08-19 all collections (notes, articles, replies) are PuSH-subscribable feeds.
- Posting UI as of 2012-09-09: http://aaronparecki.com/2012/253/note/3
Sandeep Shetty
User:Sandeep.io First post POSSE'd on 2012-11-05. I primarily syndicate to Twitter using a very lo-fi solution of adding silo (Facebook, Twiiter, Google+) provided share links to each post that I can manually click to prefill content, edit and post. I've avoided API integration because of the extensive experience I've had using Facebook API and dealing with it's random changes. "Integration" has high costs sometimes so I keep it as simple as possible.
Ben Werdmuller
werd.io as of 2013-05-31 [9]. Ben Werdmuller implemented POSSE in his idno platform via plugins. New content has an associated Activity Streams object type; POSSE plugins listen for post events associated with those object types and syndicate appropriately.
- Notes and articles are syndicated to Twitter and Facebook
- Images are syndicated to Facebook, Flickr and Twitter
- Places are syndicated to Foursquare
- More plugins are very easily possible; the Foursquare plugin took about an hour to build
Shane Becker
- Shane Becker using Dark Matter on veganstraightedge.com (since 2013-07-17[10]) with automatic rel-syndication markup on manual POSSEing:
Glenn Jones
glennjones.net as of 2014-01-14 Glenn Jones The blog implemented POSSE using a new version of transmat.io system. New content added to transmat is associated with objects types. A POSSE twitter plugins listens for post events syndicating content. At moment only notes are syndicated.
Jeremy Keith
adactio.com as of 2014-05-27 Jeremy Keith has implemented POSSE using his own custom CMS.
- Notes have been POSSEd since he first started posting them on his own site, on 2014-05-27 (Note POSSE copy may say 2014-05-26 presumably because of timezone differences, Jeremy's is in BST, while a PDT viewer sees datetime adjusted accordingly). See also related blog post 2014-06-01.
- Photos have been POSSEd to Twitter since he first started posting them on his own site on 2014-07-05 and to Flickr since 2014-07-08. Examples:
- http://adactio.com/notes/6978/
- http://adactio.com/notes/7021 - first photo POSSEd to both Twitter and Flickr:
Shane Hudson
shanehudson.net as of 2014-09-19 Shane Hudson has implemented POSSE to Twitter for Craft CMS.
- Previously working on Wordpress but he was not keen on the UX.
- Has reply contexts working but has to manually copy the ID.
- Not yet POSSEing photos but plans to.
- Currently he has to manually copy the tweet from the main text box to a 140 character limit tweet text box. He plans to make that automatic.
Ravi Sagar
http://www.ravisagar.in/blog/implementing-posse-my-site Implementing POSSE on my site as of 2018-02-21.
- The new blogs and notes are posted on Drupal
- http://www.ravisagar.in/rss-social.xml RSS Feed is generated for the blogs and notes tagged with "Share" keyword
- Using Rebrandly to create shortlinks for the RSS Feed
- Using Zapier to share the newly created rebrandly links to Twitter and Linkedin
Ludovic Chabant
ludovic.chabant.com as of 2018-07-30 Ludovic Chabant has implement POSSE to Twitter and Mastodon from PieCrust CMS, using SiloRider
- SiloRider is CMS independent -- it only relies on Microformats found in the published markup.
- New articles are posted as title and link.
- New microblogging updates are mostly copied verbatim (if the fit the external service's character limits), and support photo posts, including multi-photo posts.
Adam Dawkins
adamdawkins.uk as of 2019-01-16 Adam Dawkins has implemented POSSE using his own custom CMS.
- Notes have been POSSEd since he first started posting them on his own site, on 2019-01-16
Examples
Shaun Ewing
shaun.net as of 2020-01-16 Shaun Ewing has implemented POSSE using Jekyll, and custom APIs.
- More information https://shaun.net/notes/taking-back-control-of-my-content/
- Syndication is still manual, and I'm still working on Level 3/4 "IndieMark" items such as WebMentions, etc.
capjamesg
 capjamesg has been syndicating his notes from his own site to:
capjamesg has been syndicating his notes from his own site to:
- Twitter using brid.gy
- micro.blog using micro.blog's feed polling system
- The fediverse using fed.brid.gy
This syndication happens automatically whenever James posts a note using his Micropub client or his Microsub feed reader.
... add more here ...
... Add a link to your POSSE–enabled site and the date you started syndicating copies of your content out to 3rd party social sharing/publishing services.
Partial POSSE sites
Sites which only POSSE some of their content, and still post directly to the same silo they POSSE to.
Other partial POSSE sites:
- User:Hupili.net implements a partial POSSE with the following setups:
- SNSAPI is a lightweight middleware to unify the data structure and interfaces of different social networking services. It gives the scripting flexibility for developer users to manipulate social silos.
- SNSRouter is a web UI built upon SNSAPI where one can read an aggregated timeline from different sites, mass forward messages, and update statuses on all channels.
- As is said in one of the description paragraph above, this model is not truly POSSE. One can not (hardly) distinguish original/ syndicated status. I'm planning to put a page with permlink on my site upon each status update and then use SNSAPI to syndicate to other silos.
Other Approaches
COPE
COPE is short for Create Once, Publish Everywhere (COPE), which explicitly lacks a first "Publish Once" step, and thus is more about duplicating the content across various destinations.
Without a first "Publish Once" step on a site you "Own", and thus lacking original post permalinks, the COPE strategy fails to actually draw people to any one canonical place to read/view your stuff, and thus all it does is grow (likely) disjoint audiences across other people’s sites.
Articles:
- 2009-10-13 COPE: Create Once, Publish Everywhere by Daniel Jacobson, Director of Application Development for NPR. (Original https://www.programmableweb.com/news/cope-create-once-publish-everywhere/2009/10/13 offline due to site-death of programmableweb.com in 2022)
- 2019-10-28 Create Once, Publish Everywhere With WordPress by Leonardo Losovitz in Smashing Magazine
- 2019 WordCamp Taipei talk: Create Once, Publish Everywhere video on WordPress.tv
POSE
POSE, Publish Once Syndicate Everywhere, was a broader predecessor of POSSE that also included publishing once on one particular silo, and then syndicating out to other silos.
PESOS
A similar but opposite approach is PESOS where content is posted first to 3rd party services and then copied/syndicated into a personal site.
If exact copies of content are posted on both a personal site and 3rd party services, there's no way to tell (short of comparing possibly non-existent sub-second accurate published dates) whether a site is using POSSE or PESOS. Sites can provably support POSSE by including perma(short)links in syndicated copies that link/reference back to published originals.
PESETAS
PESETAS is like PESOS but copying/syndicating everything to a particular silo (without any involvement of a personal site).
For example, most silos support cross-posting to Twitter, thus you could connect everything to your Twitter account and always (auto-)cross-post there to keep a copy.
E.g. Tumblr has a UI for cross-posting to Twitter. See Webapps StackExchange post for documentation and screenshots of UI.
Tumblr is a better PESETAS destination however, since it is well established, allows for a wider variety of content, and allows more text, and links to URLs directly instead of linkwrapping them like Twitter does.
Brainstorming
CRUD
All of the above, and to date (2013-222), POSSE has solely described syndicating the Creation of content on your site (publishing) to other sites. This model has been quite successful and perhaps may be sufficient.
However, it is worth exploring the potential utility of a full CRUD protocol for POSSE.
Create
Create is the POSSE default. You create content on your site, you POSSE your creates to other sites. All of this is described above, and in silo-specific details on silo pages.
Read
Read as a verb is interesting when applied to POSSE.
At a minimum, it's useful to implement storing links to syndicated copies of your content to provide for the future possibility of reading from downstream POSSE copies.
See:
- u-syndication for how to markup links to syndicated copies of your content
- syndication-link-use-cases for why to do so
Actual direct uses of Reading from downstream POSSE copies:
- reverse-syndication / backfeed of activity around the POSSE copy onto your original:
In addition, keeping a u-syndication link to the POSSE copy enables deleting it to perform an Update or a Delete action, as described in the following sections.
Update
If a POSSE destination allows updates/edits, then when you edit your post, you could propagate that update to the downstream POSSE copy as well.
- E.g. Facebook allows editing the text of a post (including any links in the text), person tags, but not the image of a photo post
If the destination disallows updates/edits, like Twitter, it is still possible to virtually POSSE updates by deleting the POSSE tweet and reposting, i.e.:
Consider only POSSEing updates to Twitter:
- if no one has replied to it yet (otherwise you'd break a threaded conversation on Twitter)
- if your changes would be shown in the truncated copy on Twitter (i.e. if your changes are past the 140 (more like 120) character horizon, no point in churning the Twitter copy).
- within a very short time window, maybe like 2-5 minutes, because otherwise the update will be seen as a duplicate to people who are reading you on Twitter.
All of these concerns are regarding the experience that you provide to your friends reading your tweets on Twitter, which of course should be the whole (design) reason you're bothering to POSSE to Twitter in the first place.
For details, see silo-specific POSSE sections:
- Facebook: POSSE to Facebook (to-do: needs details re: edit text ok, but no photo editing, photo posts need delete/repost to simulate POSSE update)
- Flickr: (UI supports manually updating the image of a photo post, but is that available in the API? and if so, file a Bridgy Publish feature request GitHub issue to support POSSE Update to Flickr (including the image of a photo post)
- Twitter: POSSE to Twitter (to-do: copy the above delete/repost strategy to there)
- ...
Delete
Deletes seem fairly straightforward to POSSE, especially to services which themselves propagate deletes to clients.
E.g. one can delete a note on Twitter at any point.
Similar to updates, consider:
- if there are already replies to a POSSE copy (or activity like favorites/retweets), consider keeping it to keep conversation threading (and others' favorites/retweets).
However, if you really feel like deleting the content from your site and POSSE copies (e.g. on Twitter), go ahead and do so.
Perhaps this is an opportunity for the UI for the deletion of a post to check to see if there's been any activity (replies, favorites, retweets) on the POSSE copy before performing the delete. One possible implementation could involve the UI informing the user of this activity (or lack of it) and reconfirming the delete request on a per-service basis.
IndieWeb Examples
 Grant Richmond supports POSSE deletes on twitter as of 2018-10-10, by checking if a post on his site has been unpublished / deleted and sending the appropriate api request for likes, reposts and notes.
Grant Richmond supports POSSE deletes on twitter as of 2018-10-10, by checking if a post on his site has been unpublished / deleted and sending the appropriate api request for likes, reposts and notes.
FAQ
Worry about search engines and duplicates
Q: Do we need to worry about search engines penalizing apparently duplicate posts?
A: That's why the POSSE copies SHOULD always link back to the originals. So that search engines can infer that the copies are just copies. Ideally POSSE copies on silos should use rel-canonical to link back to the originals, but even without explicit rel-canonical, the explicit link back to the original is a strong hint that it is an original.
This is also an advantage of POSSE over PESOS. With PESOS - there's no way to tell what's the original and what's the copy - so they do look like duplicates.
POSSE-post-discovery and backlinks
Q: Brid.gy can use posse-post-discovery to find the relationship between a syndicated post and the original when there is not explicit link. Does this mean I should stop adding backlinks to syndicated copies?
A: POSSEing without a backlink is considered a last resort, and has some costs associated with it. See posse-post-discovery#Tradeoffs for more details.
POSSE or Send Webmentions First
In short, POSSE first, then send webmentions.
See: Webmention FAQ: POSSE or Send Webmentions First for details and reasoning.
Background
- 2010-05-26 POSSE first described online as a concept in Tantek Celik on DiSo 2.0: Down to Brass Tacks(archived monkinetic original) :
Publish on your own site, own your URLs, your permalinks, and
Syndicate out to other sites. Your text updates to Twitter, your checkins to Foursquare, your photos to Flickr etc. - 2010-10-06 POSSE+backfeed conceptual architecture (predating the terms)
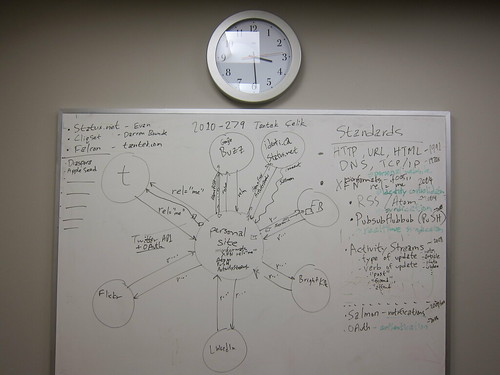
Note the arrows to/from the "Personal site" in the middle. Arrows outward are conceptually illustrating POSSE, while those returning, backfeed.
See 2011-01-10 post relating/expanding on it: On Owning Your Data: Follow-up to @Zeldman and the #indieweb - 2011-06-25 IndieWebCamp 2011 session: "Publish Then Syndicate and Replicate" further explored POSSE conceptually.
- 2012-06-21 POSSE term defined: http://tantek.com/2012/173/t1/posse-core-indieweb-approach
Related conceptually:
- sometime before 2014-06-21[11]: POSE (Publish Once Syndicate Everywhere) term defined at some point prior to POSSE. Conceptually it was looser than POSSE, as "once" could be interpreted as on a silo rather than your "own site", which POSSE (and the conceptual predecessors) made explicit.
Articles
Articles and blog posts about POSSE, especially implementing it:
- : Hipster
- An audience/context-conscious POSSE syndication plugin for WordPress
- (Ars Technica) How Google’s AMP project speeds up the Web—by sandblasting HTML
[…] this nudges publishers toward an idea that's big in the IndieWeb movement: Publish (on your) Own Site, Syndicate Elsewhere (or POSSE for short).
The idea is to own the canonical copy of the content on your own site but then to send that content everywhere you can. Or rather, everywhere you want to reach your readers. Facebook Instant Article? Sure, hook up the RSS feed. Apple News? Send the feed over there, too. AMP? Sure, generate an AMP page. No need to stop there—tap the new Medium API and half a dozen others as well.
Reading is a fragmented experience. Some people will love reading on the Web, some via RSS in their favorite reader, some in Facebook Instant Articles, some via AMP pages on Twitter, some via Lynx in their terminal running on a restored TRS-80 (seriously, it can be done. See below). The beauty of the POSSE approach is that you can reach them all from a single, canonical source.
[…]
For the Web's sake, let's hope Google sticks with AMP long enough to convince publishers that the real future is speeding up their own pages and embracing a POSSE-style approach.
- 2018-07-31 Ben Werdmüller: Stepping back from POSSE (archived)
- 2023-10-23 : The poster’s guide to the internet of the future (archived)
- Mentions POSSE by name, micro.blog, Bridgy, and links to this page
- ...
POSSE as methodology for non-web scenarios
POSSE git repositories
As discussed #indieweb it is also possible POSSE your git repositories to git "silos", such as GitHub or GitLab. An easy way of doing this was described by 
Sessions
- 2011: Publish Then Syndicate and Replicate
- 2013/Secure Cross-Posting
- 2014/SF/possepatterns
- 2016/Brighton/howposse
- 2016/StaticPOSSE
- 2016/Dusseldorf/syndication
- 2017/Berlin/possepesos
- 2019/Amsterdam/syndication
- 2019/NYC/syndication
- 2019/Düsseldorf/syndicate
- 2024/Brighton/posse
See Also
- POSSE reply
- PESOS
- PESETAS
- why
- original post link
- microsyntax for POSSEing to plain text destinations
- rel-canonical
- Documentation on syndication formats
- posts-elsewhere
- 2017-11-09 Nicolas Hoizey: Medium is only an edge server of your POSSE CDN, your own blog is the origin
- 2018-03-24 Hacker News comment thread: https://news.ycombinator.com/item?id=16663850
- HN ibid: "Why won't a link on these platforms suffice since they have their "cards"?"
- HN ibid: "This is an interesting thing, but too complicated and over-broad for the mere-mortal." <-- page introduction needs simplifying, simpler instructions to setup POSSE, acknowledge where POSSE usability is in the Generations spectrum
- HN ibid: "Facebook is just a glorified RSS feed with centralized discover ability." <-- debunk with comparing Facebook#Features (and Twitter#Features) vs RSS plumbing feature set. A visual diagram/table comparison might help.
- HN ibid: "This really is not possible with RSS at all, especially since the silos don’t want to support RSS in any meaningful way." <-- perhaps add a whole subsection in "Why" explaining why RSS is insufficient compared to POSSE.
- 2021-11-07 Hacker News comment thread: https://news.ycombinator.com/item?id=29115696
- Recommend non-realtime POSSE to Twitter and other social media due to their active use as part of the surveillance apparatus of local and national law enforcement: https://theintercept.com/2020/07/09/twitter-dataminr-police-spy-surveillance-black-lives-matter-protests/
- Jetpack 8.9 adds Social Previews which allows one to preview how your posts will appear on Facebook, Twitter, and Google search results before you hit the publish button!
- Consider a deliberate ethical use of POSSEing, e.g. see Code of Ethics for an example set of explicit self-stated “Rules of engagement”
- “Pluralistic is my mutli-channel publishing effort – a project to push the limits of POSSE (post own site, share everywhere)” Pluralistic: 05 May 2021
- Cory Doctorow explains how he uses POSSE. This Week in Google (time offset 474s): https://www.youtube.com/watch?v=qyU2cZLFsik&t=474s
I try not to get locked into anyone else’s walled garden. I … pursue this publishing strategy they call POSSE, post own site syndicate everywhere …
- articles: 2018-02-06 Dries Buytaert To PESOS or to POSSE? and 2018-02-16 Dries Buytaert My POSSE plan for evolving my site
- https://twitter.com/SaraSoueidan/status/1539870410317221888
- "What Matthias said.
Write on your own blogs, syndicate elsewhere.
Own your content! There's nothing like it." @SaraSoueidan June 23, 2022
- "What Matthias said.
- Brainstorm:
 Tantek Çelik: POSSE advantages are largely distribution (immediately) and discovery (over time). if neither of those two are happening, then it's not worth keeping it around. Date-time-proof-of-posting can be solved by sending your original post (or a POSSE/tweet copy) to the Internet Archive and does not require keeping the POSSE/tweet copy.
Tantek Çelik: POSSE advantages are largely distribution (immediately) and discovery (over time). if neither of those two are happening, then it's not worth keeping it around. Date-time-proof-of-posting can be solved by sending your original post (or a POSSE/tweet copy) to the Internet Archive and does not require keeping the POSSE/tweet copy. - https://andy-bell.co.uk/how-im-dealing-with-twitter-in-a-hands-off-manner/
- Why: 2023-07-13
 Jeremy Keith: The syndicate
Jeremy Keith: The syndicate We’ll see how long it lasts. We’ll see how long any of them last. Today’s social media darlings are tomorrow’s Friendster and MySpace.
When the current crop of services wither and die, my own website will still remain in full bloom.
- https://mastodon.social/@davidpierce/111284796654263440
- "For the last six months or so I've been obsessed with POSSE, a decade-old idea about how to mix the best of blogging and social media. For a story and for The Vergecast, I tried to figure out how POSSE could work — and why it might not https://www.theverge.com/2023/10/23/23928550/posse-posting-activitypub-standard-twitter-tumblr-mastodon" @davidpierce October 23, 2023
- to-do: draw an updated diagram without Twitter (replace with Bluesky), and to Fediverse via BridgyFed with a line that ends in "Y" with 📤 📥 on the ends
- update any references / instructions to POSSE to Twitter to note historical importance and current lack of automated support
- to-do: add a http://micro.blog section to the "How to" section; make sure to link to micro.blog
- Why: 2024-02-24 Pluralistic: Vice surrenders
This is the moment for POSSE (Post Own Site, Share Everywhere), a strategy that sees social media as a strategy for bringing readers to channels that you control
- Curation is the last best hope of intelligent discourse.
- https://hachyderm.io/@pluralistic@mamot.fr/111987590552793552
- ^ actual permalink: https://mamot.fr/@pluralistic/111987590098901216
- "If there was ever a moment when the obvious, catastrophic, imminent risk of trusting Big Tech intermediaries to sit between you and your customers or audience, it was now. This is *not* the moment to be "social first." This is the moment for POSSE (Post Own Site, Share Everywhere), a strategy that sees social media as a strategy for bringing readers to channels that *you* control:https://pluralistic.net/2022/02/19/now-we-are-two/#two-much-posse14/" @pluralistic February 24, 2024
- 2024-03-09 Molly White: POSSE
I just finally deployed something I've been working on for a few weeks now: a feed of my writing, posting, reading, and other various activity that lives on my website at https://www.mollywhite.net/feed
- Why: to have another way to search your stuff, since sometimes (often? usually now?) large web web search engines like Google or even DDG are very poor at site-specific searching (e.g. site:http://tantek.com), whereas social media silos like Twitter are very good at profile-specific searches (e.g. from:t).
- IndieWeb Example: 2024-03-09 Molly White deployed automatic POSSE to Twitter/Mastodon/Bluesky: POSSE