database-antipattern

 “Whoever dropped the elevators database please restore it from backups so I can go outside.”
“Whoever dropped the elevators database please restore it from backups so I can go outside.”
The database antipattern is the false assumption that a database is the best option for primary long-term storage of posts and other personal content (like on an indieweb site). Disadvantages include additional maintenance costs, uninspectability of the raw data, platform-dependence, and long-term fragility of databases and their storage files, as documented with specific examples below.
Is this your first time on IndieWeb.org?
- See our home page and principles for an overview of what we're about.
Do you have a personal site or want one? start here:
community split
The indieweb community is nearly evenly split about the database-antipattern, as measured by what projects we use on our live sites:
- file-storage projects
- database projects
Split experience too: while there are significant experiences (documented below) with the database-antipattern, it is by no means a universally agreed upon aspect of indieweb sites or the indiewebcamp community. A few have even noted their complete lack of first-hand negative experience.
databases for storage
Using databases for the primary storage of content on your personal site is considered by some in the community to be an antipattern.
Common content management systems (e.g. WordPress, Drupal, MediaWiki, etc.) use databases for primary storage of content. Most often MySQL, sometimes others like MongoDB.
Databases are all a pain to maintain (i.e. highly human-time inefficient - see DBA tax below), and more fragile[1] than the file system.
For any content you care about, don't put the primary copy in a database.
DBA tax
(this likely deserves its own canonical definitional article)
DBA tax (a form of admin tax) refers to the extra overhead you as a person incur by depending on any system that uses a database for primary storage. If you maintain any such system, you have to spend some amount of your time being a database administrator (DBA), hence that time spent is referred to as the DBA tax that you are incurring.
In particular, a database is yet another space of things.
Everyone already deals with a file system. Why deal with yet another space?
The following are aspects of the DBA tax - hassles of:
- setting up a database
- setting up tables
- setting up username/login that is database specific
- altering tables
- dealing with username/login that is database specific (often gets in the way of things, e.g. password reset on MediaWiki)[2]
- exporting/importing
- backups (separate from the backups you're already doing of the file system, because database files can themselves become corrupted internally - as what happened with Magnolia).
- underlying data store requiring manual upgrades when updating database software
All extra crap (thus tax) compared to "just" using the file system.
All databases have a DBA tax.
Experience and evidence shows DBA tax exists as well. People lose things (and have them corrupted) in databases all the time, far more often than in file systems. This is because databases always require extra "magic" for backups etc.
E.g. search the web for people complaining about having to backup their WordPress databases before upgrading their WordPress install.
More examples:
- 2018-01-06
 Ben Werdmüller https://twitter.com/benwerd/status/949749939927621633
Ben Werdmüller https://twitter.com/benwerd/status/949749939927621633
Emphasis added.… I want to go back to real blogging, but I’m sick of doing server maintenance / software upgrades. Just saw my DB is down again, ffs. Moving to static files before too long.
Uninspectability
Even in databases that use only a single file (e.g. SQLite?), that "one file" is still uninspectable, as opposed to simple HTML you can always look at in a browser.
There are many reasons why an uninspectable/random/binary magic file format is fragile, whereas HTML is an inspectable file format that many tools can read/write, including a simple text editor. In particular:
- one implementation. magic database formats typically only work with one implementation. In contrast, HTML is a well documented format that supported by numerous tools (1:1 like text editors, and higher level tools) which makes it much more robust/reliable than any database file format. Similar problems occur with proprietary binary formats in general.
Platform trap
Most databases tend to be biased/tied to a particular programming language (or operating system) as well - more unnecessary constraints - trapping you into a particular platform (language or OS).
In contrast, every language / OS has flat file APIs. Nearly all have DOM Document APIs as well.
Fragile
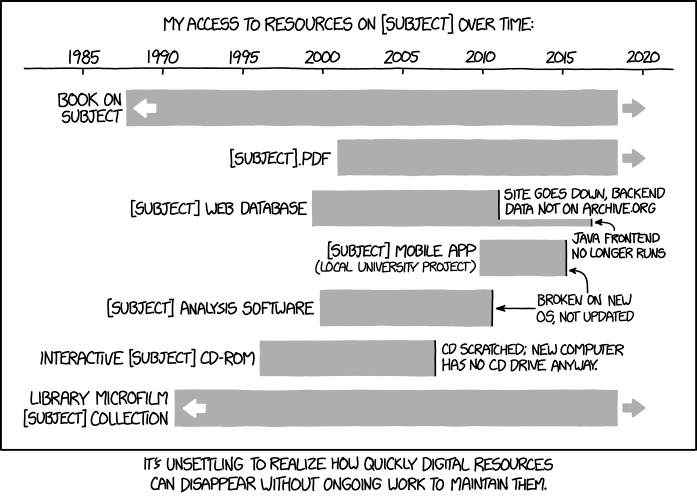
Corrupt Content
https://coronavirustechhandbook.com/
Unfortunately, due to a database issue back in June, some of the handbook content was corrupted. It can be restored through a manual process, and volunteers are working to bring the Handbook back online page-by-page. If the link to a page you would like to access is not live, and you have some time to help bring it back online, please fill out this form to request edit access. Your contribution of time--from one hour to a couple of days to an ongoing commitment to the project--would be much appreciated. Otherwise, please check back and we hope to have the rest of the handbook back online soon.
Emphasis added.
Breaks UTF-8 by default
MySQL in particular has so many ways of breaking UTF-8 content that even developers who have used it for years (decades?) still struggle with UTF-8 corruption problems either in a database, or when importing/exporting to/from a database.
Examples:
- MySQL upgrades can silently corrupt content, e.g. when "porting" - e.g. UTF8/encoding problems. Just search for MySQL UTF8. Eric Meyer has written a few blog posts about it (e.g. 2009-11-19 Correcting Corrupted Characters, and he was just doing WordPress to WordPress migrations, and worse yet - he got LOTS of *wrong* advice from those in the "MySQL community"). And the corruption is often invisible, especially if most of your content is just ASCII7. You don't notice it until long after the original where you ported from is gone and you can't do any attempt at reporting.
- I find this example misleading/disingenuous. MySQL itself does not "corrupt content all the time when porting." The common scenario I have come across is the default character encoding of a mysql database is latin1 at the time it was set up, then UTF-8 data was inserted at a later time. When the data is queried later, and latin1 encoding is still specified (e.g. the default), then the UTF-8 data will be displayed in latin1 encoding. And obviously most UTF-8 characters do not map to latin1, so "garbage" characters are displayed. This is not a unique situation to MySQL, though, or really an example of it doing anything improperly. If you save UTF-8 characters in a latin1-encoded text file, you would experience the same garbage character problem. I believe the moral of the story with this example is to always use UTF-8 from the start. — gRegor (talk) 11:58, 21 April 2014 (PDT)
- gRegor - Eric Meyer is a very intelligent person and has still had numerous problems over the years with MySQL upgrades and migrations. I've made the language more specific than "all the time" and added citations if you want to learn more about the details. Tantek 12:07, 21 April 2014 (PDT)
- I find this example misleading/disingenuous. MySQL itself does not "corrupt content all the time when porting." The common scenario I have come across is the default character encoding of a mysql database is latin1 at the time it was set up, then UTF-8 data was inserted at a later time. When the data is queried later, and latin1 encoding is still specified (e.g. the default), then the UTF-8 data will be displayed in latin1 encoding. And obviously most UTF-8 characters do not map to latin1, so "garbage" characters are displayed. This is not a unique situation to MySQL, though, or really an example of it doing anything improperly. If you save UTF-8 characters in a latin1-encoded text file, you would experience the same garbage character problem. I believe the moral of the story with this example is to always use UTF-8 from the start. — gRegor (talk) 11:58, 21 April 2014 (PDT)
- 2016-07-04 as part of rename to IndieWeb, it was discovered that UTF8 in the IRC logs was being mistreated by MySQL
- Doesn't handle emojis by default. Emojis take 4 bytes in UTF-8 encoding and the default "utf8" data type handles up to 3 byte characters. You need to update your columns and tables to "utf8mb4", which creates a whole new set of interesting problems.
Follow-up: Q: Isn't MySQL trivial to port via: mysqldump ... | scp | mysql ?
- A: No, not trivial. Although this is often the most reliable way to migrate data between different MySQL versions, it is still easy to encounter UTF8 corruptions unless you are extremely careful about UTF8 settings on both ends. Don't forget the --skip-extended-insert flag otherwise if you have really large tables they will break when the target DB has a smaller max query size!
Corrupt Tables
I was getting 'mysql crashed' so I did 'repair' on the tables, and then the homepage and /travel were blank. I imported a backup from 25th but it wouldn't import, said there was a primary key collision. ... when I did the mysql repair it screwed up some keys in the database to point the object of the published triple to the id of another post, because ARC2 has this complicated database structure to turn relational into a graph that I haven't bothered to understand properly
http://rhiaro.co.uk/2016/04/fixed-websitelast
MySQL hard reset
Databases are known to be fragile in exceptional situations, e.g. high traffic load, server hard restart. Real world example: MySQL and Rackspace:
... Bad news: MySQL barfed all over the table holding my posts. ... [3]
And I'm pretty sure that happened when Rackspace hard reset my machine due to swapping.[4]
Note: apparently Postgres doesn't have that problem.
DB connection loss
Often (but not always) database server software runs on a separate machine and/or process than the web server, and thus it's possible for the connection between the two to go down, for who knows what reasons, e.g. 2014-10-02 Keybase DB connection lost:
@aaronpk @KeybaseIO Yeah we lost the DB connection in our Web process so all queries were failing. Weird, first time we've seen that bug.
Maintaining / checking / restoring this "connection" is yet another source of DBA tax.
This is apparently a frequent occurrence:
- Google "Database+Connection+Lost"
- Google "Database Error" "Error establishing a database connection" for actual sites that are down and indexed as such.
- Specific example found during another Google search: http://krispysbytes.org/tag/publish-once-syndicate-everywhere/ - page returns
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>Database Error</title> </head> <body> <h1>Error establishing a database connection</h1> </body> </html>
- Specific example found during another Google search: http://krispysbytes.org/tag/publish-once-syndicate-everywhere/ - page returns
So much so that phishers use it as a way to trick WordPress users into submitting their username/pw:
Too many connections
Sometimes the reason some code "failed to open the DB connection" is "Too many connections"
For example here is a PHP CDbException found in the wild for "Too many connections"

Caching ok
Databases are useful for caching/performance needs for high volume sites. Examples:
- aggregations (e.g. all of your posts with a specific tag) can be cached.
- full-text search index
- geo-search index
In both search use-cases the DBs should be a cache/query store, the real data should still be in flat files (e.g. .md, HTML, etc.) to ensure long-term durability.
Premature Optimization
Even though databases are fine for rebuildable caches, that's still solving an optimization problem.
Any design that depends on databases is optimizing prematurely - before you have any idea what the performance characteristics of the system are.
Alternatives
Rather than using a database for storage, use open well established formats like markdown or HTML + microformats, and if you really like how databases let you access them, instead build a database-like API on top (of said markdown or HTML + microformats files).
- See file-storage for details on specific approaches.
With HTML+microformats2 + a microformats2 parser, we already have a database-like API that gives you data back from HTML.
It's likely that eventually we'll come up with something resembling a database / storage API on top of an HTML+microformats2 file.
- What do mean by a storage /database API on top of an HTML file?
- Something where you can get back structured data and potentially write structured data. E.g. the phpmf2 microformat2 parser/API, perhaps even based on micropub.
FAQ
Why discuss storage plumbing
Q: Whenever people advocate or deep dive into specific backend tools here, we often say, "that's plumbing, we prefer to focus on end-user use-cases" (and maybe interop) here, but why do we make an exception for database vs flat files, which we dive into, even though it's still plumbing?
A: Summary: when the choice of plumbing strongly impacts the UX, then it is worth documenting problems, issues, advantages, disadvantages, and tradeoffs among choices in plumbing. By the same measure, any criticism not tied to UX should be moved to the specific technology impacted, rather than technology area or approach.
Specifically, UX impact on users and general usage is the focus. UX that only affects developers approaches a plumbing debate which is not necessarily productive.
Negative UX impacts from this use of databases tend to be in two categories:
- fragility = your website goes down / away / corrupted or, loses functionality, has unreliable functionality = very bad UX
- DBA tax = maintaining your website consumes more of your otherwise free time (also impacts your UX of using your website since it is more demanding for non-content oriented tasks).
Examples of UX impact:
Should I never use a database
Q: What, you mean, never use a database ever? That's crazy! How on earth could you build (some big service) without a database?
- A: There are instances where the benefits to using a database offset the additional costs of using a database (e.g. large services for large numbers of users). There are also instances where the costs are mitigated or reduced (e.g. caching only).
This page is specifically about the problems and undue burdens that database usage causes people that maintain their own indieweb sites, and documentation their real-world personal frustrations and issues with databases.
This doesn't mean that you should never use a database: judge technology in a sensible way.
Some popular database systems are overkill for some use cases around personal publishing. If you are trying to build a large scale, multi-user system, this page might not apply to you.
If you are building a personal publishing platform, or archiving content you’ve spent hours/days/years creating, then there are actual tradeoffs (in terms of complexity, management etc.) that you need to think about.
SQLite tax avoidance
Q: Is SQLite a way to avoid the DBA tax?
- A: No. It's still yet another space of stuff and one space of stuff is easier to maintain / keep track of than two spaces of stuff. It also still has the "one implementation" fragility of its magic file format.
How are database file formats random
Q: How are database file formats random?
- A: One way is that they're random over time - the implementation changes, the format changes typically in lockstep. If you're lucky you may be able to import/export across versions or different versions of the implementation may corrupt different versions of the file format. Hence database file formats are both semi-random (unpredictable future), and frankly, potentially randomizing (corrupting).
MySQL portability
Q: Isn't MySQL pretty portable?
- A: No. That's actually a huge misconception. It might be portable if all you have is very small amounts of short data all in ASCII7. Change any of those and you're likely to experience invisible corruption when moving MySQL data from one instance to another.
Examples:
- MySQL upgrades can blow away databases, and then fail to reimport. Citation:
- 2005-03-09 Eric Meyer: Stuck
I upgraded my local copy of MySQL, and it blew away my WordPress database. So I mysqldumped the database from meyerweb.com, copied it down to my hard drive, and tried to mysqlimport it. And tried, and tried, and tried, until eventually my eyes started bleeding. No dice.
- 2005-03-09 Eric Meyer: Stuck
- MySQL installs can break when migrating between laptops. Citation:
- 2012-04-27 Eric Meyer https://twitter.com/meyerweb/status/195940443060572160
Apparently when I migrated laptops, the MySQL install broke and must be fixed. Thus begins another afternoon of me screaming at my machine.
- 2012-04-27 Eric Meyer https://twitter.com/meyerweb/status/195940443060572160
See also Breaks UTF-8 by default.
PaaS Compatibility
Q: Flat-file storage prevents you from using Heroku, Google AppEngine, or other PaaS's. Is that a different kind of "Platform trap"?
A:Yes. If you can't easily scp/rsync files to/from your host or PaaS, then any files created there are "trapped" as well.
Database with export
Q: Would using a database with an export to HTML w/ microformats (or other durable format) files mitigate these concerns?
A: It could mitigate those concerns to the extent that you trust your code to be able to import from those files as well as export to those files any time you create/save user content in your databases. And at that point (where you have dependable code to import/export from/to flat files), consider directly using the flat files, and only using an intermediate database for caching purposes (if you need that, the section on "databases for caching").
Still not convinced
Q: Still not convinced that databases for storage are an anti-pattern or about the DBA tax.
- A: For those still not convinced, it's left as an exercise to lose enough data in random/binary file formats over the years until it's painful enough that you decide to stop using such things for anything you care about. If you don't think it's a pain, the only likely way to learn that it is is by doing it for years. Go ahead and try to make databases for primary storage work if you like, and report back on how well your data is doing in a few years (like 10).
Isn't flat-files a form of database?
Q: This page seems to be advocating flat file storage. But that is just a form of database. This is so hypocritical.
- A: Yes, it is a database, albeit a different sort of database. One that is portable, has broad cross-platform support, that you're already backing up. Why do you need two databases with twice the hassle?
You may also feel free to consider this page to be titled "the big, overly complicated databases with non-trivial maintenance antipattern".
Finally, this wiki is itself hosted on MediaWiki, which stores data in MySQL. So there's that - as an issue of practicality, it may be less costly (time etc.) for some use-cases to re-use existing solutions with a database and bear the DBA tax, than attempt to write your own solution (see wiki-page for work in progress on that use-case in particular).
Q: I don't understand how this anti pattern is related to the indieweb?
- A: In one word: longevity. Part of the reason we are frustrated with silos are their inevitable site-deaths and loss of content and permalinks, thus one of the indieweb principles is building for the long web longevity. And as soon as you start thinking & designing for longevity you realize longevity of your content and data (including permalinks) is critical, and when you design for that, you find that databases are bad for longevity and thus their common use as primary long-term storage is an antipattern.
Does a dynamic site need a databases
"Q: Does this mean I can’t have a dynamic site without a database?"
A: Not at all! Not using a database as the primary storage for your content doesn’t mean you have to use static hosting. Your dynamic web application can read data out of the filesystem just as it would an opaque database, without all the disadvantages mentioned above. Falcon is one real world indieweb example of flat file storage based dynamic post content server.
Articles
Related articles:
- 2013-11-17 My Favorite Database is the Network
- : Software is not data (Ed. and thus in particular, database software is not data)
Spreadsheets and databases are complex programs written to enable users to do marvellous things with data, but only if the data are kept within those applications. That trade-off isn't widely appreciated.
- 2015-03-06 Martin Kleppmann: Turning the database inside-out with Apache Samza
- 2016-09-02 @mipsytipsy:
"can you come up with any ways databases might fail?" they asked. 5 min of brainsplotting @honeycombio

See Also
- database
- file-storage
- MySQL
- MongoDB
- Postgres
- database-cache
- antipatterns
- projects
- https://github.com/gfredericks/quinedb/blob/master/README.md
- http://imgur.com/r/ImagesOfThe2010s/dgR5T
- https://dev.to/kellogh/sql-is-insecure
- https://twitter.com/grambulf/status/826758178272587777
- https://github.com/idno/Known/issues/1702
- ACM Hypertext Conference site for 2008 as of 2017-12-29:
Database Error: Unable to connect to the Database: Could not connect to MySQL.Database Error: Unable to connect to the Database: Could not connect to MySQL.
- Matt Webb “I count static HTML as data :) and way more robust than databases over that time period (my blog has been plain text files for 20 years, rendering/editing code changed a half dozen times)” https://twitter.com/genmon/status/1251256228057174017
- "I count static HTML as data :) and way more robust than databases over that time period (my blog has been plain text files for 20 years, rendering/editing code changed a half dozen times)" @genmon April 17, 2020
- Error establishing a database connection
- https://twitter.com/timbray/status/1254143366914162688?s=20
- "1/ Dear LazyWeb, need an obscure database recommendation. So, I’m migrating my blog from my 2014 Mac to new 16" Catalina box. I wrote it in 2002 and it’s in Perl. Has a backing database in mysql. However, it’s essentially impossible to use DBD::mysql on Catalina." @timbray April 25, 2020
- from Folksonomies: how to do things with words on social media -- OxfordWords blog:
From a narratological perspective, it would probably be fair to say that most databases are tragic. In their design, the configuration of their user interfaces, the selection of their contents, and the indexes that manage their workings, most databases are limited when set against the full scope of the field of information they seek to map and the knowledge of the people who created them. In creating a database, we fight against the constraints of the universe – the categories we use to sort out the world; the limitations of time and money and technology – and succumb to them.
- Semi-humorous threadtree of various database criticisms: https://twitter.com/rbranson/status/1512444259143614466
- "We're cancelling each other over database takes today. Post your cancellable database take." @rbranson April 8, 2022
- Counter-argument for SQLLite in particular: Its storage format is a US Library of Congress Recommended Storage Format for datasets per https://www.sqlite.org/locrsf.html and https://www.loc.gov/preservation/digital/formats/fdd/fdd000461.shtml#local
- https://twitter.com/jogbert/status/1532105996209889281
- "This person wins Reddit for this answer on "How to mock DBs"" @jogbert June 1, 2022
- ^

- opaque database files more vulnerable to human error to correct synchronization errors: 2023-01-19 FAA NOTAM Statement
- ^
contract personnel unintentionally deleted files while working to correct synchronization between the live primary database and a backup database. The agency has so far found no evidence of a cyber-attack or malicious intent.
- ^ 2023-01-19 NPR: FAA contractors deleted files — and inadvertently grounded thousands of flights
the shutdown happened as the contractors worked to "correct synchronization between the live primary database and a backup database."
- https://about.gitlab.com/blog/2017/02/10/postmortem-of-database-outage-of-january-31/
- Why not databases: 2023-07-01 File over app
…most of these artifacts are out of our control. They are stored on servers, in databases, gated behind an internet connection, and login to a cloud service.