search
🔍
search in the IndieWeb usually refers to searching your personal site for your own content (and/or caches of content you’ve responded to), sometimes searching IndieWeb chat archives or the IndieWeb wiki, or the nascent IndieWeb Search index and service to search across community posts.
Why
Why should your site be searchable?
- You want your independently created and owned content to be found and preferably above and before content on silos.
Why should your site have a search feature?
- The ability to easily search IndieWeb sites is a very commonly requested feature by readers / users of said sites.
- They don't want to have to think to go to Google (and take extra steps) to search your site.
- Make it easy for your friends that read your site to find stuff there by having a simple search box in the top right of every page (common UI convention) that allows the user to type something in and perform a search on your site. You can of course use 3rd party search engine to do this, even returning results directly from them. E.g. using a Google search box on your site.
- Website visitors can find exactly what they are looking for without having to search through pages of feeds or archives.
Why Not
There are sometimes reasons you don't want a particular page or section of your site to not be indexed for searching. E.g.
- Private / private by obscurity URLs
- Dynamic aggregations, e.g. tag aggregation pages, archives (by date etc.), because you'd rather that just the post permalinks themselves get indexed to reduce noise in search results.
How
How to implement search on your site.
searchability - level 1
Make sure your site is at least searchable (IndieMark search level 1). This means:
- allow robots to index. Permissive or no robots.txt. Either don't have /robots.txt (easiest), or if you have one, it MUST allow search engines to index public posts on your site.
- post content in HTML. Your post content MUST be in the visible HTML of the page retrieved from your post permalink. No depending on Javascript to render your post content - if you can't curl it, it's not on the web.
- site-specific searchability. Be able to use "site:yoursite.example.com search-term" in Google and other search engines (that support site-specific searches) directly to find and display your posts in search results.
search box - level 2
Add a simple search box to your site using a static form that submits to a search engine to provide time ordered (most recent first) results! (IndieMark search level 2)
E.g.
<form class="search" action="http://www.google.com/search" method="get"> <input type="hidden" name="as_sitesearch" value="example.com"/> <input type="hidden" name="tbs" value="sbd:1,cdr:1,cd_min:1/1/1970"/> <input type="search" name="q"/> <button type="submit">Search</button> </form>
And change example.com to your personal site name! This HTML has been tested live since 2012-07-06.
Search form styling is left as an exercise for the creator.
site search with 3rd party backend - level 3
Search where your site uses a 3rd party search service (e.g. Google), but still provides the results on your own domain. (IndieMark search level 3)
How to TBD.
Third Party Search Services
site search with site backend - level 4
Search where your site handles all the indexing and search queries. (IndieMark search level 4)
How to TBD.
Software
- gigablast, C++
- MeiliSearch, Rust with Rest API
- OpenSearchServer, Java
- OpenWebSpider, C#
- Omega (Xapian frontend), C++
- regain, Java,
- sphider, PHP
- phinde, PHP - running on http://search.cweiske.de/ and https://indiechat.search.cweiske.de/
- TSEP The Search Engine Project, PHP
- DataparkSearch Engine
- TNTSearch - full-text search engine written in PHP
- SQLite with FTS4 or FTS5 engine, queried with PHP, Python, etc.
- Whoosh, Python
- Typesense open-source search service (hosted version available) - comparison
self-hacked engines
- Self hosted search engine with elasticsearch, Calaca as frontend and apache nutch as crawler
- Self hosted search engine hacked together as a CGI script in bash using grep naïvely.
client side search
has been suggested as possible level 5? Not really better than lvl 4, more an alternative solution, especially for static sites.
How to TBD.
Start with: http://lunrjs.com/ I.e.:
- Background XHR your recent content storage files to the client
- Feed them in structured form to lunr.js to build an index
- Enhance your search box / form with JS to do it all clientside if you have a lunr.js search index available
How To Avoid
For all the reasons above in Why Not, here's how to avoid having specific pages not be indexed:
Put this in the head of your page you don't want indexed:
<meta name="robots" content="noindex,follow" />
This instructs the crawler to not add the page to it's index, but to follow links contained in it. If you don't want it to consider links either, change follow to nofollow.
IndieWeb Examples
IndieWeb sites that have search interfaces.
Tantek
![]() Tantek Çelik has had a search interface on his site tantek.com since 2012-07-06 which uses a simple static form that submits to Google search (IndieMark search level 2).
Tantek Çelik has had a search interface on his site tantek.com since 2012-07-06 which uses a simple static form that submits to Google search (IndieMark search level 2).
Aaron Parecki
From 2012-07 to 2016-01,  Aaron Parecki had a search interface on his site aaronparecki.com which used a simple static form that posted to to Google search scoped to the website and with query parameters that indicate to Google to return posts in reverse date order (IndieMark search level 2).
Aaron Parecki had a search interface on his site aaronparecki.com which used a simple static form that posted to to Google search scoped to the website and with query parameters that indicate to Google to return posts in reverse date order (IndieMark search level 2).
Since 2016-08 there is a search interface which searches a local index of posts, returning the list of matching posts rendered in normal list format in reverse date order (IndieMark search level 4).
Since 2020-06 the local search has been expanded to include searching the contents of reposts and likes, as well as the authors of those posts. e.g. https://aaronparecki.com/search?q=tantek
Ben Werdmuller
 Ben Werdmüller has had a search interface on his site werd.io since (2013-06-20) which uses his own site's backend (MongoDB in particular). (IndieMark search level 4).
Ben Werdmüller has had a search interface on his site werd.io since (2013-06-20) which uses his own site's backend (MongoDB in particular). (IndieMark search level 4).
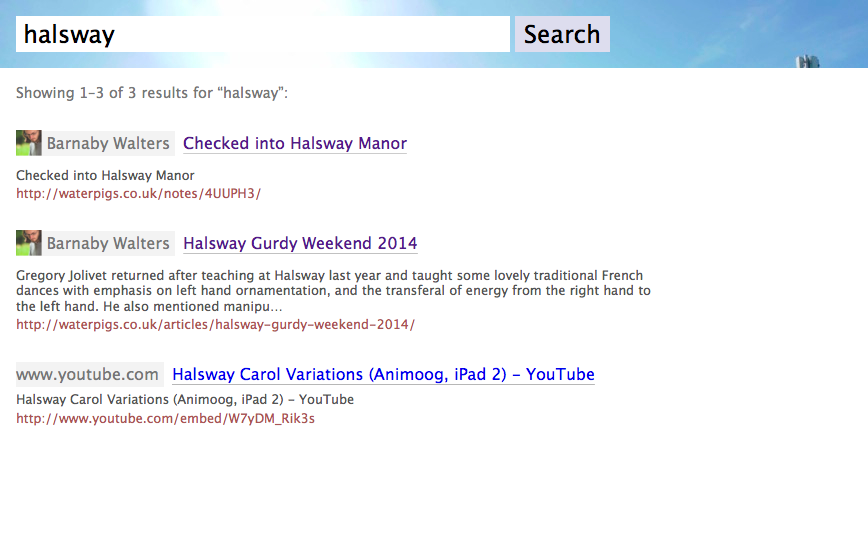
Barnaby Walters
 Barnaby Walters added a simple static search form (based on Tantek’s code) to waterpigs.co.uk on 2014-02-24 which submits to a site-scoped Google search (IndieMark search level 2).
Barnaby Walters added a simple static search form (based on Tantek’s code) to waterpigs.co.uk on 2014-02-24 which submits to a site-scoped Google search (IndieMark search level 2).
Also experimenting with local search engine which indexes the archive of all the pages I’ve linked to as well as mentions of my own pages using Elasticsearch.
UI as of 2014-03-01, showing authorship information, page name, excerpt, URL:
Dan Lyke
 Dan Lyke has had locally hosted search since March of 2001, and currently has a simple search which uses his PostgreSQL back-end text indexes, and does some ordering of search results based on phrases, and "+" and "-" to require and exclude. (IndieMark search level 4).
Dan Lyke has had locally hosted search since March of 2001, and currently has a simple search which uses his PostgreSQL back-end text indexes, and does some ordering of search results based on phrases, and "+" and "-" to require and exclude. (IndieMark search level 4).
Since I'm scanning various other sites for inbound links, I'd like to, at some point, index those other sites as well for additional search options.
Ben Roberts
![]() Ben Roberts has a search box on his site since 2014-09-30 which simply submits to Google search (IndieMark search level 2) ordered by most recent post.
Ben Roberts has a search box on his site since 2014-09-30 which simply submits to Google search (IndieMark search level 2) ordered by most recent post.
Kyle Mahan
 Kyle Mahan previously had local search backed by Postgres full text matching (@@ operator) on 2015-01-16. Posts were presented as a standard h-feed, but I'd wanted to style them more like "search results" (and have more results per page) in the future.
Kyle Mahan previously had local search backed by Postgres full text matching (@@ operator) on 2015-01-16. Posts were presented as a standard h-feed, but I'd wanted to style them more like "search results" (and have more results per page) in the future.
In 2016-01, I converted my site to Known, which uses MySQL full text search by default.
Christian Weiske


phinde supports faceted browsing on tags, domain, language and file type. It indexes not only the blog but all linked URLs. Crawling, indexing and the HTML frontend are written in PHP, data storage and searching is done in ElasticSearch.
The search form is available on the blog index and tag index pages, as well on single blog posts.
phinde is also used for indieweb chat log search at https://indiechat.search.cweiske.de/
gRegor Morrill
 gRegor Morrill added local search to gregorlove.com for articles and notes on 2016-06-05 (IndieMark search level 4).
gRegor Morrill added local search to gregorlove.com for articles and notes on 2016-06-05 (IndieMark search level 4).
- As of 2017-04-21, the search form has been moved to only appear at https://gregorlove.com/search. This page is linked from the footer of each page. I moved it in part because page footers were looking cluttered, and my usage of search is relatively infrequent. My current thinking is that it's fine to have it only on the /search URL.
- Previously: The search form is the bottom of each page and has fields for filtering by before/after date.
- Uses the ProcessWire API to search. Defaults to full-text queries, but uses like queries for shorter text.
Jamie Tanna
 Jamie Tanna has re-enabled search on his static Hugo site since 2019-05-01
Jamie Tanna has re-enabled search on his static Hugo site since 2019-05-01
Murray (theAdhocracy)
 Murray uses Algolia to power search on his static Gatsby site since 2020-05-09
Murray uses Algolia to power search on his static Gatsby site since 2020-05-09
capjamesg
 capjamesg previously maintained a custom search engine using Python Flask and sqlite3 for his blog. The search engine was composed of a crawler which crawles and processes all posts and images into an index and a web server that lets you query the index.
capjamesg previously maintained a custom search engine using Python Flask and sqlite3 for his blog. The search engine was composed of a crawler which crawles and processes all posts and images into an index and a web server that lets you query the index.
The search engine supports two types of pages:
- Regular pages (blog posts, the homepage, and all other html pages on my site)
- Images
This search engine is no longer live and has been deprecated. The code behind capjamesg's search engine has evolved into IndieWeb Search, a search engine for the IndieWeb community.
You can search James' site using a site search filter on IndieWeb Search like this:
site:"jamesg.blog" coffee
The Doctor
Drwho.virtadpt.net has finally gotten around to adding a 'real' search engine to their website using their favorite general purpose search engine software. The search engine went online on 26 July 2021 on a separate server they control. The entire site was crawled to bootstrap the index and then the RSS feed was added to the YaCy scheduler to pull new posts and pages into the indexer.
A blog post that describes how it was done and integrated into their static website was posted as part of the #libreops movement in the Fediverse.
Anthony Ciccarello
 Anthony Ciccarello has had a /search page since 2023-01-09 with a search box and three suggested search engines.
Anthony Ciccarello has had a /search page since 2023-01-09 with a search box and three suggested search engines.
Design
If in doubt: copy Google (when it was still searching for relevant keywords, and was without the first page of ads)
Search UI
To start with, no need for anything more than a single-line text box and “Search” button — keep things focused.
Indexing
Due to widespread use of microformats on the indieweb, each page being indexed is rich in semantics which can be indexed e.g. explicit name, publication datetime authorship information, relations like in-reply-to, representative image, etc.
Some properties can be faked if microformats markup isn’t present:
- name can be substituted with the contents of the
titleelement
Many semantics similar to microformats ones can be found in invisible metadata like OGP meta elements — whether or not it can be trusted or gives a better search experience requires further experimentation.
You may choose to use other structured data formats for indexing if your website supports them. For instance, you may choose to use JSON-LD, a type of linked structured data, in your indexing if your site is rich in JSON-LD syntax.
Structured data makes it much easier for you to index pages since you can rely on your implementation of a structured data standard when indexing information. For instance, using microformats means you could get any category on a page by looking for the p-category property. Finding a category without structured data present would be much more difficult.
To get the best results a plaintext representation of each page should be indexed. In lieu of a HTML to Plaintext algorithm, some steps to follow include:
- Remove the
headelement from the page - Remove any other
script,styleelements from the page - Replace embedded content (e.g. images, videos, audio) with it’s text-based accessible fallback e.g.
altattribute for images - …
You might opt not to index a plaintext representation of a page depending on what search features you want to allow. Indexing a whole page takes up significantly more space than indexing only meta descriptions, titles, and some information from a page, especially if you have a very large repository of content.
Result Display
Results should be displayed in order of relevance by default. Having the option to order search results by datetime might also be useful, depending on the data you want to represent. For instance, a search engine of blog posts on your site may benefit from a reverse-datetime order.
Each result should form a block with clear visual thingness separating it from other results. A click anywhere on the block should navigate immediately to the search result URL, which should be shown in it’s entirety at the bottom of the block.
- the only reason I can think of to not navigate immediately, i.e. navigate via an intermediate redirect is to check whether or not the page exists and show an archived copy instead. Perhaps that checking is better left to a browser extension which acts only on a 404 --Barnaby Walters 09:51, 28 February 2014 (PST)
Search results should link directly to the page to which they are linking, without any intermediary links. Intermediary links are sometimes used for tracking by search engines.
Search results from the same site should be nested to a maximum depth of 2, as long as both results follow each other on the search page. Search engines like Google and IndieWeb Search use this layout to indicate that content is part of the same site. The way IndieWeb Search does this is pictured below:

Two of James' coffee posts are nested above the first result because they all appear in order.
Search result pages should not display too many results on one page if meta descriptions / images / article descriptions are used. Showing too much content on a page may make your search page slower to load and less accessible to those using mobile devices and who are on limited data plans.
Ranking factors
You may choose to weigh a certain set of ranking factors to help improve "relevance" of your search engine. For instance, you may decide to weigh titles as more important than content in meta descriptions. Ranking factors to consider:
- Title tags
- Meta descriptions
- Image alt text (if you are adding image support to your search engine)
- Keywords (either identified by an algorithm or those specified in a meta tag)
- H2s
- H3s, H4s, H5s, and H6s.
- Word count
- Links pointing to a page on your site from other sites (external backlinks)
- Links pointing to a page on your site from your site (internal links)
- The anchor text used in links pointing to a web page
- and more...
Ranking factors are something you should consider if you have a large repository of content and want to maximize the chance that visitors find a result that meets their needs.
Links as a ranking factor
Search engines often use links as a ranking signal. The basic theory behind using links to rank search results is that the more sites that link to a web page, the more likely that site is to be authoritative on a particular subject matter. For a smaller scale or personal search engine, you may just want to count the links between pages as a way of ensuring that the most relevant results are returned for a post.
Advanced Filters
Google Search, and many other search engines like GitHub's search feature, support advanced filters that make it easy to find what you are looking for. On Google, these include:
- inurl:
- intitle:
- "specific term"
- AND
- OR
You can read more about advanced filters on Goggle in this article: https://ahrefs.com/blog/google-advanced-search-operators/
You might also opt to add custom advanced filters based on your needs (i.e. a filter that returns posts published in a specific tag or category).
Some database full text search features, such as the SQLite full text search, already support filters like AND and OR. If you are using a database full text search feature, you should read their documentation to learn about what filters might already be available to you without implementing them directly.
Image search
It is possible to add image search support to a personal search engine. This is a nice feature to add if you have a lot of images on your site through which you want to search. Having this feature would make it easier for you to find what images you have used and perhaps find images to reuse in future posts or pages.
Image searches are most effective if you have alt text through which to search.
You can index results for image search as part of your regular text index. You should have a separate table in a database for image searching as you will need to keep track of different attributes. A basic image search index should keep track of:
- Image URL
- Image alt text (through which you will search)
- The title of the post associated with the image
These attributes will provide a solid foundation that will make it easy for you to find images based on keywords.
Searchability Preferences
Mastodon
Mastodon allows users of the site to set preferences as to how findable their content is.

Silo Examples
Twitter 2011
Some old screenshots of Twitter's search UI from a 2011 blog post:
Simple search:

Advanced search:

Criticism of Existing Search
- Criticism: Google Search sucks for personal site search, especially older posts: 2018-01-15 (updated 2022-02) Tim Bray: Google Memory Loss
- https://twitter.com/max_oats/status/1521801590432497664?s=21&t=IsZYNl69qAub0WWa-7qsIA
- "google in 2022 is dogshit bc if i want to search "check mouse dpi" it comes up with 10000000 AI-driven tech blogs of which the content is eighteen paragraphs of:
What is the DPI Mouse?
Many people would like to check their DPI of mouse. The DPI of a mouse is the dots-per-second" @max_oats May 4, 2022
- "google in 2022 is dogshit bc if i want to search "check mouse dpi" it comes up with 10000000 AI-driven tech blogs of which the content is eighteen paragraphs of:
- Google's "helpful content update" that uses a machine learning model to classify content that is written more for people vs. search engines: https://developers.google.com/search/blog/2022/08/helpful-content-update
Brainstorming
Sessions
Search related sessions at past IndieWebCamps:
Faceted scoped search
Beyond raw searching of the contents of your site, it may also be useful to index and be able to search within:
- a time window (from/to dates/times)
- a geography (location proximity, within an area / polygon)
- person mentions
Site plus links search
Beyond searching just the contents of what you publish on your own indieweb site, it may be useful to *also* index:
- every page that you link to in your posts
And then provide results from those as well as your own site.
Site plus linked sites
Beyond searching just the contents of what you publish on your own indieweb site, it may be useful to *also* index:
- every site of pages that you link to in your posts, perhaps using PuSH discovery for those sites.
And then provide results from those as well as your own site.
- Use-case: searching your posts and the webmentions they have received using web search tools, good reason to store received webmentions and render them server-side: https://twitter.com/megarush1024/status/1034332413911023616
- "That time you search through all the posts on your site because you know you complained about Spotify’s suggestion algo when you have a playlist on shuffle and it something lame, and you know @jage9 told you how to fix it in a Twitter reply that came back as a webmention." @megarush1024 August 28, 2018
Social search
Beyond searching just the contents of what you publish on your own indieweb site, it may be useful to *also* index:
- every indieweb site of any person you mention
- in your posts
- sidebar
- friends lists
- etc. anywhere on your site.
- every site you follow in your indie reader
And then provide results from their sites as well as your own site.
- Others have expressed desire for a modern Technorati based on the IndieWeb https://social.coop/@jsit/109744623736322473
- "@axbom @eric I wish we had an #indieweb Technorati. I want to browse and subscribe to people blogging around certain tags again." @jsit January 24, 2023
Drawbacks
Indexing all of this content by one's self would be difficult to maintain as you mention more people on your site. Search engines require some degree of maintenance to prevent dead, duplicate, and malformed links from occupying spaces in search results.
IndieWeb Examples
capjamesg
capjamesg has added an IndieWeb Search integration into his Microsub reader. This integration lets him discover new IndieWeb community members to follow. The integration makes use of a "discover" feature on IndieWeb Search. This feature only returns results for words that show up in a site's h-card.
More brainstorms
See additional brainstorms at:
- phinde, my self-hosted search engine
- IndieWeb Google Custom Search Engine
- Indie Search resource list maintained by Aram Zucker-Scharff aka Aram Z-S
- How would one build a search engine today? - lobste.rs
- https://wiki.nikitavoloboev.xyz/web/search-engines (archive)
- http://www.norvig.com/spell-correct.html
- https://cloud.google.com/blog/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology
- A demo video showing a "personal" search index: https://twitter.com/morgallant/status/1511792083534704643
- "What doing research should look like in 2022. In this case, asking the @Cloudflare blog about the effect of earthquakes on internet traffic patterns." @morgallant April 6, 2022
- Implementing TextRank on my blog search engine
Alternate Search Engines
- A text-focused search engine: https://search.marginalia.nu/
- A different way to think about search: https://you.com/
- https://wiki.nikiv.dev/web/search-engines large list of search engines and search related resources here.
- https://search.marginalia.nu/
- There are many people and businesses working on new takes on search that contain new ideas: https://dkb.io/post/the-next-google
- A small search tool for searching across related "sister sites" or other digital gardens : http://www.wikigraph.net/gardensearch; see https://twitter.com/BillSeitz/status/1510770230469050368
- Wiby - Search Engine for the Classic Web, which indexes pages that are manually submitted
See Also
- Getting Started
- IndieMark
- reader
- OpenSearch
- IndieWeb Search
- "Keeping my follows on my site as an OPML file allows me to use Inoreader for OPML subscribe. Then I can use their built-in search (and saved searches) to get information from personal websites I’m following." @Chris Aldrich September 29, 2020
- How to add a custom search engine to Firefox
- option for JS-based client-side search generated from static pages: https://pagefind.app/
- Brainstorming: Pagefind looks worth looking into for SSG-based sites per https://fosstodon.org/@JanMiksovsky/111738503715709420
- ^ IndieWeb Example using Pagefind: https://www.zachleat.com/search/